
Cleaning Inconsistent Data (School Names) for the EcoMitram App
Tackling inconsistent school names with fuzzy matching for accurate participant counts in the EcoMitram App.

I am volunteering for the development of the EcoMitram App. While conducting online quizzes for students across India, I encountered a significant challenge. We didn't have a comprehensive list of schools and institutions and instead relied on students to provide their school names during registration. Unfortunately, the data we collected was riddled with inconsistencies, making it difficult to identify the number of participants from each school.
Exporting the Data from MongoDB
The dataset we were working with consisted of school names and participant data, exported from MongoDB. Notably, the inclusion of city-name facilitated grouping within MongoDB, but resolving the naming inconsistencies remained a formidable task.
Below is the MongoDB aggregation query used to fetch grouped data from the MongoDB database:
[
{
$match:
{
type: "nspc23",
},
},
{
$project:
{
"participant.institutionName": 1,
"participant.class": 1,
"participant.location.pincode": 1,
"participant.location.city": 1,
"participant.location.state": 1,
},
},
{
$group:
{
_id: {
$toLower: {
$concat: [
"$participant.institutionName",
"(",
{
$ifNull: [
"$participant.location.city",
"BLANK",
],
},
")",
],
},
},
count: {
$sum: 1,
},
school: {
$first: "$participant.institutionName",
},
pincode: {
$first: "$participant.location.pincode",
},
city: {
$first: "$participant.location.city",
},
state: {
$first: {
$ifNull: [
"$participant.location.state",
"BLANK",
],
},
},
},
},
{
$sort:
{
count: -1,
city: 1,
school: 1,
},
},
]
The MongoDB Query to Export the Data. it was very important to sort the data by decreasing count of records and adding Cityname to groupBy clause.
There were 3 important lessons we learned -
- Using School and City Name to Group the Records: That the only we can merge the same name school from different cities
- Handle the NULL value of City (where we don't have location data): if any value is null in the concat operation, the result becomes null, so the data will be merged with some other city
- Sort the data with decreasing count: This way, when we merge later, we give priority to the school names provided by many rather than giving priority to any first discovered name. (will be important for fuzzy merging)
Analyzing the Exported Data
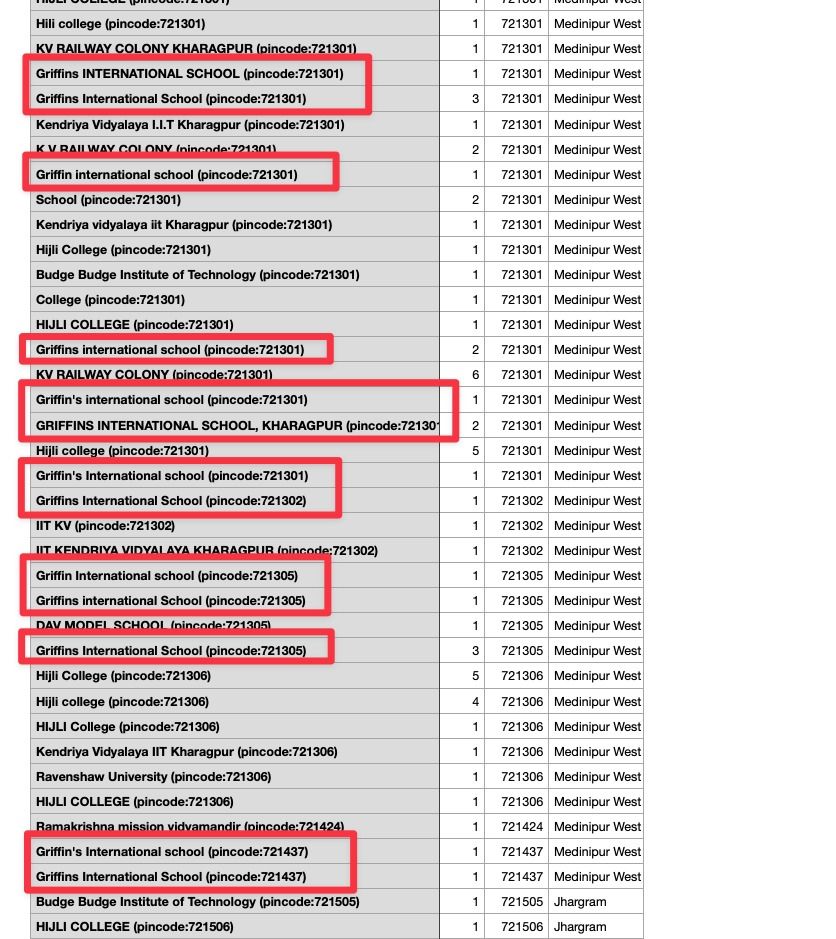
Upon examining the dataset closely, it became clear that many students used various abbreviations, misspellings, and randomly added City or Locality in school names when providing their school names. This led to a proliferation of duplicate entries, making it impossible to obtain an accurate count of participants from each school. It was clear that a simple string-matching approach would not be sufficient to address this issue.
Cleaning the Data
To avoid merging schools with the same names but located in different cities, I incorporated CityName data into the solution. While the school names were often inconsistent, the CityName provided a reliable indicator of location. By considering the CityName along with fuzzy matching, I could differentiate between schools with similar names but distinct locations.
To merge the schools with similar name provided within a city, We cleaned the names of schools provided by students using the below function.
- Many students used the name of city in school name,
- Many students used the school word in the name of school
- Random spaces or special characters were also common
- Abbervation was also a common practice, but that is not feasible to merge with full name
function cleanName(name, city) {
name = name.trim();
//lowercase
name = name.toLowerCase();
name = name.replaceAll('-', ' ')
name = name.replaceAll('.', ' ')
name = name.replaceAll('"', '')
name = name.replaceAll(',', '')
//remove city names
name = name.replaceAll(city.toLowerCase(), "");
//remove school
name = name.replaceAll('school', "");
//remove non alpha-numeric, with space
name = name.replace("/[^a-z0-9 ]/g", " ");
name = name.trim();
return name;
}Finally, Merging the School Names
To tackle this challenge, I decided to implement fuzzy string-matching algorithms. Fuzzy matching allows for approximate string comparisons, taking into account differences in spelling, abbreviations, and slight variations in the text. By leveraging this technique, I aimed to merge duplicate entries and accurately determine the number of participants from each school or institution.
Below is the code snippet for the fuzzy merging of school names:
const cityFuzzyMap = {};
csvData.forEach((row, index) => {
//read the data
const [nameWithCity, count, origName, pincode, city, state] = row;
//clean the school name
const name = cleanName(origName, city);
// Use separate fuzzyset for every city
let fuzzyMapKey = `${city}:${state}`;
if (cityFuzzyMap[fuzzyMapKey] === undefined) {
cityFuzzyMap[fuzzyMapKey] = FuzzySet();
}
const fuzzyMap = cityFuzzyMap[fuzzyMapKey];
// Check if there is a fuzzy match for the name
matches = fuzzyMap.get(name, null, 0.75);
if (matches) {
//It a match with a previously discovered name
saveRecord(row, matches[0][1]);
} else {
// not a match, let's add a new school name
fuzzyMap.add(name);
saveRecord(row, name);
}
});
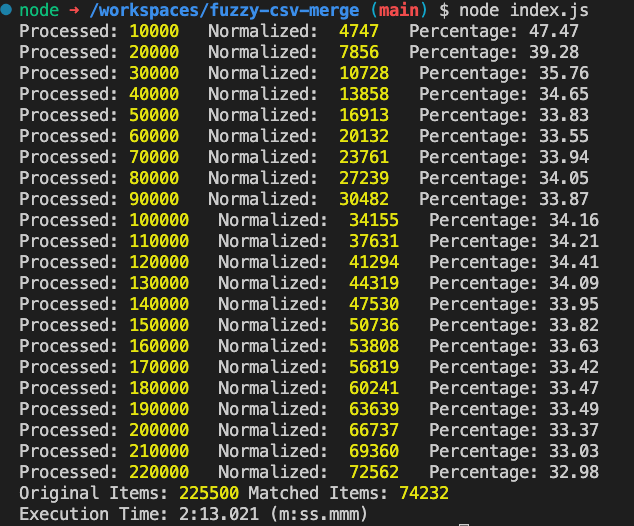
Remarkably, this endeavour resulted in the successful merger of 225,000 records into a much more manageable 74,000 entries.
You can access the complete code for this data-cleanup solution on my public GitHub repository: https://github.com/ssv445/fuzzy-merge
Further Improvements:
For our purpose, the above was sufficient cleanup. These schools can be further reduced by doing more experiments like -
- Matching School abbreviations
- Translating School names provided in non-English languages
Do you have more ideas to make it better, let me know.